In this post we’ll consider Similarity, or also called Semantic search and it’s realization with Vector databases.
Similarity and semantic search are interchangeable / similar concepts in this context.
Before digging into details, what is the difference between semantic search and plain full text search ? Text search usually assumes plain keywords matching. Semantic search is generally more intelligent, as it accounts phrase (concept) contextual meaning and relations between concepts. It kind of attempts to understand users intention to find some information, associated with the query. Semantic search usually produces more relevant results and is thus generally more efficient. Similarity search relies on natural language processing (NLP) and machine learning (ML) algorithms to analyze context and identify relationships between terms and concepts in user query.
Real life use cases for Similarity Search
- Recommendation Systems: suggesting products or content by comparing user profiles, items’ similarities or characteristics
- Knowledge Bases: e.g. Amazon Bedrock provides Knowledge Bases feature and uses Vector Databases under the hood
- NLP(Natural Language Processing): semantic search and semantic comparison of text data
- Image identification and Video Retrieval: Finding similar images or videos from large datasets; face recognition and so on
- Classification (where text strings are classified by their most similar label)
- Anomaly detection and fraud prevention
- Chat-bots and intelligent personal assistants
- and many others
How similarity Search works
In the context of semantic search or concepts similarity, each concept or phrase is represented as a vector in a high-dimensional space. In real-life practical realizations of semantic search amount of dimensions may vary from at least several hundreds to several thousands. Just imagine space with say 1500 dimensions! Here’s visual illustration of concepts, represented as Vectors in a multidimensional space:

For to perform similarity search, words or phrases (frequently referred to as word embeddings) should be converted into high-quality semantic vectors via some Transformer Model (e.g. OpenAI’s Embeddings API or SentenceTransformers describe the approach for to convert word embeddings into vector representations.
Similarity search is executed using one of the two strategies:
- cosine similarity (which is in effect a mathematical angle between concepts in multidimensional space)
- Euclidean (or L2) distance
Practical Semantic Search realization
If you’ve familiarized yourself with the fundamental Semantic Search concepts and at least 90% confident you need it in your platform or application, in this abstract we’ll consider practical realizations of Semantic Search.
Vector databases provide great Semantic Search capabilities using vector representations of concepts / word phrases.
During recent research of which Vector database to choose for Semantic Search realization we opted pgvector from Postgres as the most optimal choice. Why ? There were multiple reasons to that, like e.g.:
- extensive documentation
- wide usage and adoption of Postgres Database (and pgvector is just an extension of Postgres)
- single relational database( Postgres is in essence a relational database) and possibility to have single storage for platform data and vectors
And it appeared during implementation and testing, that pgvector was the proper choice for our needs.
Pgvector essentials
Pgvector provides both: exact and approximate neighbor search for finding the nearest neighbors of a given query embedding.
By default, pgvector performs exact nearest neighbor search, which provides perfect recall and guarantees 100% accuracy. While this is the most accurate way, it is resource intensive and leads to slow query response time. Exact nearest neighbor search performs sequential scan (full scan) and becomes costly at 50k rows.
Pgvector allows you to trade some accuracy for performance by adding one of the supported index — HNSW or IVFFlat — to use approximate nearest neighbor (ANN) search. Adding an index trades some recall for speed.
Cosine Similarity in Semantic Search
Cosine similarity is a metric used to measure how similar two vectors are, irrespective of their size. It’s calculated as the cosine of the angle between two vectors in a multi-dimensional space. This calculation results in a value between -1 and 1, where:
- 1 means the vectors are identical in orientation (pointing in the same direction),
- 0 indicates orthogonality (independent and have no similarity),
- -1 implies vectors point in diametrically opposite directions (i.e. complete dissimilarity).
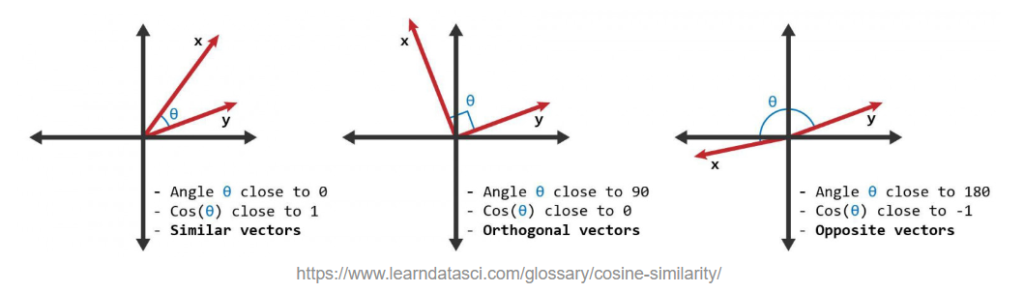
In context of semantic search, each phrase (or word embedding) is represented as a vector in a high-dimensional space. Cosine similarity quantifies how similar concepts are in terms of their content and meaning, based on the angle between their vector representations, rather than their magnitude or length.
Cosine similarity is particularly valuable and is recommended, when comparing text embeddings or analyzing document similarities based on content overlap.
Commonly used operators in pgvector
<->: this pgvector query operator calculates the Euclidean (or L2) distance between two vectors. Euclidean distance is the straight-line distance between two vectors in a multidimensional space. If the Euclidean distance between two vectors is small, that indicates greater similarity between vectors, making this operator useful in finding and ranking similar items.
`SELECT id, name, embedding, embedding <-> '[0.32, 0.1, 0.95]' as distance FROM items ORDER BY embedding <-> '[0.32, 0.1, 0.95]';`
Above query retrieves three columns id, name, embedding about items from the “items” table, calculates their distances to a specific reference vector'[0.32, 0.1, 0.95]', and then orders the results based on these distances.<=>: this operator computes the cosine distance between two vectors. Cosine similarity compares the angle orientation of two vectors rather than their magnitude
`SELECT id, name, embedding, embedding <=> '[0.32, 0.1, 0.95]' as cosine_distance`
FROM items ORDER BY embedding <=> '[0.32, 0.1, 0.95]' DESC;
Above query orders the results in descending order with the most similar items appearing first rather than simply finding the closest items in terms of Euclidean distance.<#>: this operator computes the inner product between two vectors. The inner product denotes the magnitude of an orthogonal projection of one vector onto another one. It determines whether the vectors point in the same or opposite directions. Two vectors are orthogonal to each other if their inner product is zero. It’s important to note that<#>returns the negative inner product since PostgreSQL only supportsASCorder index scans on operators.
Your choice of query operator depends on your application’s goals and the nature of your data. You can experiment with each operator to see which produces a better result for your needs.
Your choice of query operator depends on your application’s goals and the nature of your data. You can experiment with each operator to see which produces a better result for your needs.
Querying
See querying abstract in official PGVECTOR documentation.